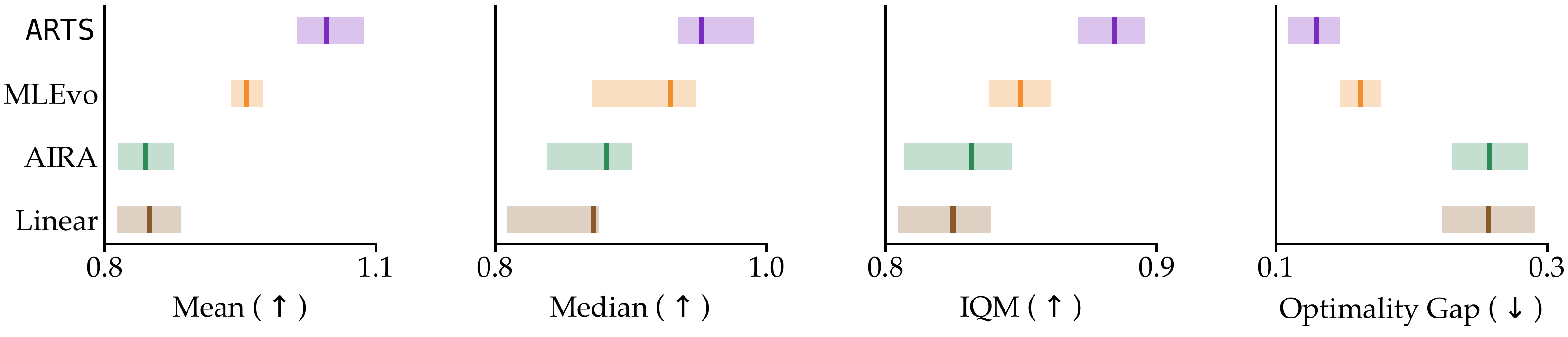
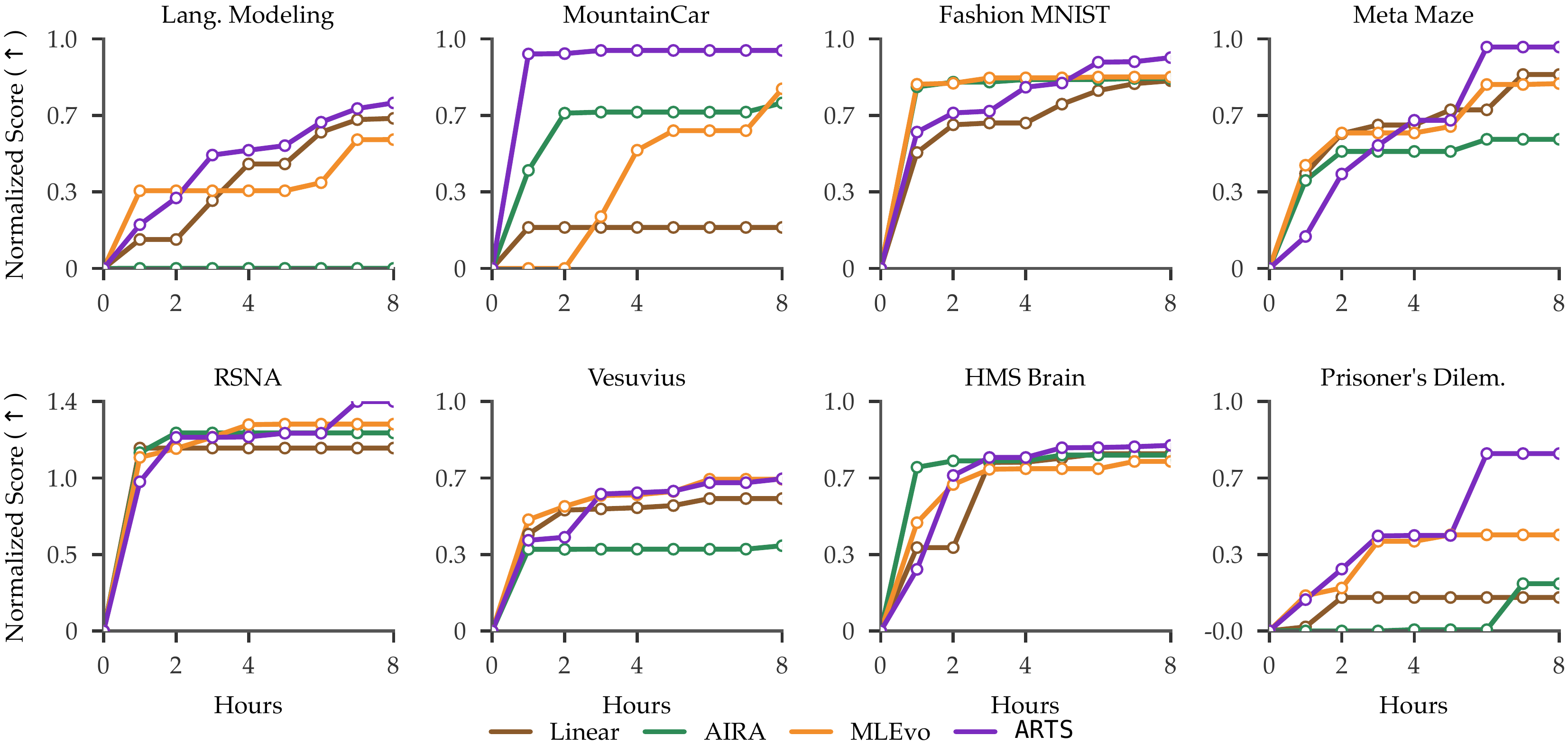
✦ Agentic Reasoning for Tree Search
Learning the ARTS of Search
for Automated Discovery
Using a reasoning agent to search the space of hypotheses instead of heuristics.
Gurusha Juneja1,
Arnav Kumar Jain2,
Deepak Nathani1,
William Yang Wang1,
Xin Eric Wang1
1University of California, Santa Barbara
·
2Université de Montréal & Mila – Quebec AI Institute
The scientist inspects each node's logs and failures to reason about why it scored low,
then proposes diverse hypotheses through verbalized sampling.
When the search history outgrows the context window, ARTS folds it into the model's weights with
test-time training — so a 4B model matches an o3-scale model
at about a fifth of the inference cost.